29 KiB
title: Contributing Code summary: Fix bugs and add new features to help make SilverStripe better.
Contributing Code - Submitting Bugfixes and Enhancements
SilverStripe will never be finished, and we need your help to keep making it better. If you're a developer a great way to get involved is to contribute patches to our modules and core codebase, fixing bugs or adding features.
The SilverStripe core modules (framework and cms), as well as some of the more popular modules are in
git version control. SilverStripe hosts its modules on github.com/silverstripe and github.com/silverstripe-labs. After installing git and creating a free github.com account, you can "fork" a module,
which creates a copy that you can commit to (see github's guide to "forking").
For other modules, our add-ons site lists the repository locations, typically using the version control system like "git".
We ask for this so that the ownership in the license is clear and unambiguous, and so that community involvement doesn't stop us from being able to continue supporting these projects. By releasing this code under a permissive license, this copyright assignment won't prevent you from using the code in any way you see fit.
Step-by-step: From forking to sending the pull request
-
Install the project through composer. The process is described in detail in "Installation through Composer".
composer create-project --keep-vcs --dev silverstripe/installer ./my/website/folder 4.0.x-dev -
Edit the
composer.json. Remove any@stablemarkers from the core modules in there. Add your fork URLs, in this example a fork of thecmsmodule on thesminneegithub account (replace with your own fork URL). Run acomposer updateafterwards."repositories": [ { "type": "vcs", "url": "git@github.com:sminnee/silverstripe-cms.git" } ], -
Add a new "upstream" remote so you can track the original repository for changes, and rebase/merge your fork as required.
cd cms git remote add -f upstream git://github.com/silverstripe/silverstripe-cms.git -
Branch for new issue and develop on issue branch
# verify current branch 'base' then branch and switch git status git checkout -b ###-description -
As time passes, the upstream repository accumulates new commits. Keep your working copy's branch and issue branch up to date by periodically rebasing your development branch on the latest upstream.
# [make sure all your changes are committed as necessary in branch] git fetch upstream git rebase upstream/3.2 -
When development is complete, squash all commit related to a single issue into a single commit.
git fetch upstream git rebase -i upstream/3.2 -
Push release candidate branch to GitHub
git push origin ###-description -
Issue pull request on GitHub. Visit your forked repository on GitHub.com and click the "Create Pull Request" button next to the new branch.
The core team is then responsible for reviewing patches and deciding if they will make it into core. If there are any problems they will follow up with you, so please ensure they have a way to contact you!
The Pull Request Process
Once your pull request is issued, it's not the end of the road. A core committer will most likely have some questions for you and may ask you to make some changes depending on discussions you have. If you've been naughty and not adhered to the coding conventions, expect a few requests to make changes so your code is in-line.
If your change is particularly significant, it may be referred to the mailing list for further community discussion.
A core committer will also "label" your PR using the labels defined in GitHub, these are to correctly classify and help find your work at a later date.
GitHub Labels
The current GitHub labels are grouped into 5 sections:
- Changes - These are designed to signal what kind of change they are and how they fit into the Semantic Versioning schema
- Impact - What impact does this bug/issue/fix have, does it break a feature completely, is it just a side effect or is it trivial and not a bit problem (but a bit annoying)
- Effort - How much effort is required to fix this issue?
- Type - What aspect of the system the PR/issue covers
- Feedback - Are we waiting on feedback, if so who from? Typically used for issues that are likely to take a while to have feedback given
| Label | Purpose |
|---|---|
| change/major | A change for the next major release (eg: 4.0) |
| change/minor | A change for the next minor release (eg: 3.x) |
| change/patch | A change for the next patch release (eg: 3.1.x) |
| impact/critical | Broken functionality for which no work around can be produced |
| impact/high | Broken functionality but can be mitigated by other non-core code changes |
| impact/medium | Unexpected behaviour but does not break functionality |
| impact/low | A nuisance but doesn't break any functionality (typos, etc) |
| effort/easy | Someone with limited SilverStripe experience could resolve |
| effort/medium | Someone with a good understanding of SilverStripe could resolve |
| effort/hard | Only an expert with SilverStripe could resolve |
| type/docs | A docs change |
| type/frontend | A change to front-end (CSS, HTML, etc) |
| feedback-required/core-team | Core team members need to give an in-depth consideration |
| feedback-required/author | This issue is awaiting feedback from the original author of the PR |
Workflow Diagram
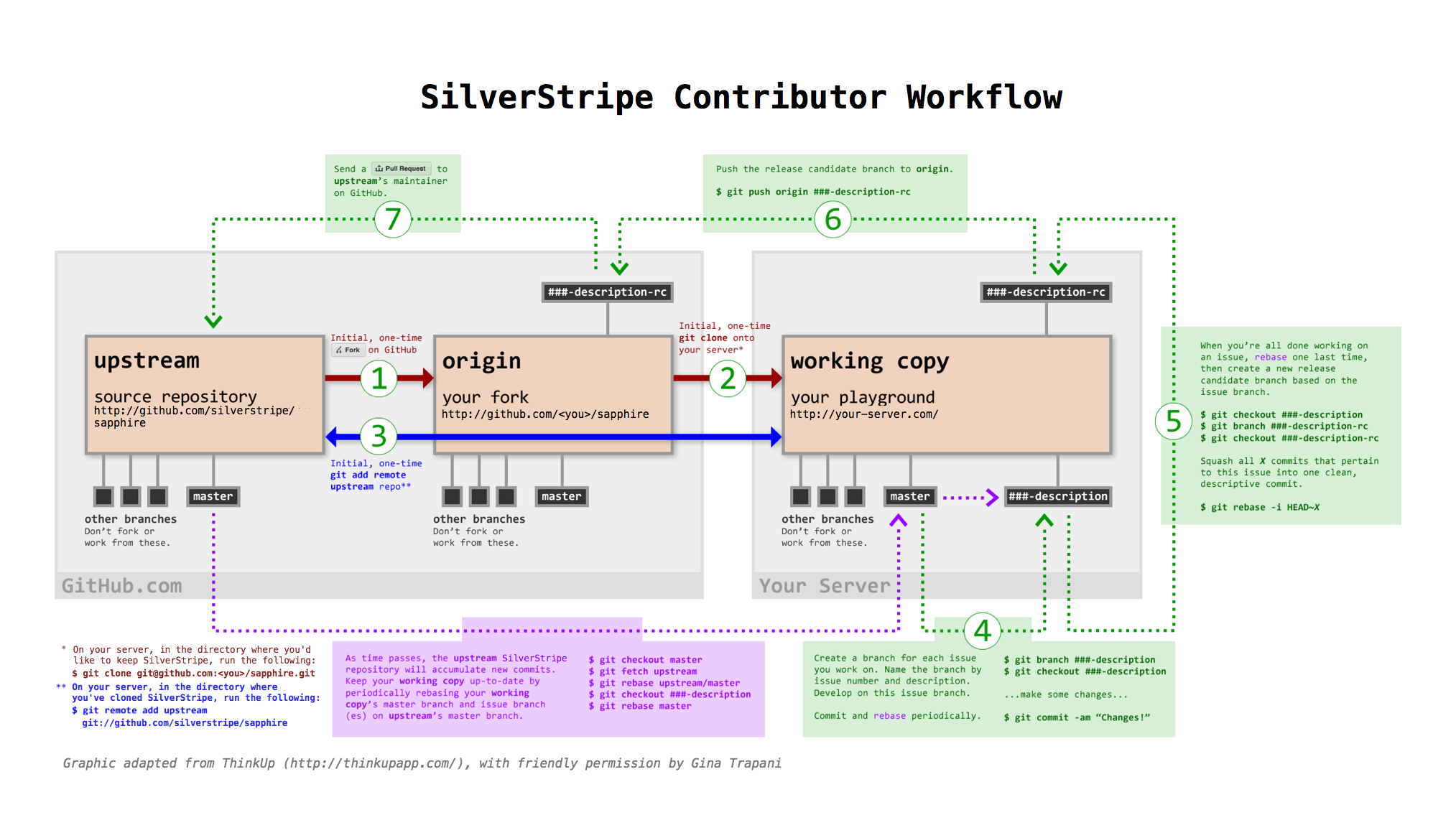
Quickfire Do's and Don't's
If you aren't familiar with git and GitHub, try reading the "GitHub bootcamp documentation". We also found the free online git book and the git crash course useful. If you're familiar with it, here's the short version of what you need to know. Once you fork and download the code:
-
Don't develop on the master branch. Always create a development branch specific to "the issue" you're working on (on our GitHub repository's issues). Name it by issue number and description. For example, if you're working on Issue #100, a
DataObject::get_one()bugfix, your development branch should be called 100-dataobject-get-one. If you decide to work on another issue mid-stream, create a new branch for that issue--don't work on both in one branch. -
Do not merge the upstream master with your development branch; rebase your branch on top of the upstream master.
-
A single development branch should represent changes related to a single issue. If you decide to work on another issue, create another branch.
-
Squash your commits, so that each commit addresses a single issue. After you rebase your work on top of the upstream master, you can squash multiple commits into one. Say, for instance, you've got three commits in related to Issue #100. Squash all three into one with the message "Description of the issue here (fixes #100)" We won't accept pull requests for multiple commits related to a single issue; it's up to you to squash and clean your commit tree. (Remember, if you squash commits you've already pushed to GitHub, you won't be able to push that same branch again. Create a new local branch, squash, and push the new squashed branch.)
-
Choose the correct branch: Assume the current release is 3.0.3, and 3.1.0 is in beta state. Most pull requests should go against the
3.1pre-release branch, only critical bugfixes against the3.0release branch. If you're changing an API or introducing a major feature, the pull request should go againstmaster(read more about our release process). Branches are periodically merged "upwards" (3.0 into 3.1, 3.1 into master).
Editing files directly on GitHub.com
If you see a typo or another small fix that needs to be made, and you don't have an installation set up for contributions, you can edit files directly in the github.com web interface. Every file view has an "edit this file" link.
After you have edited the file, GitHub will offer to create a pull request for you. This pull request will be reviewed along with other pull requests.
Check List
- Adhere to our coding conventions
- If your patch is extensive, discuss it first on the silverstripe-dev google group (ideally before doing any serious coding)
- When working on existing tickets, provide status updates through ticket comments
- Check your patches against the "master" branch, as well as the latest release branch
- Write unit tests
- Write Behat integration tests for any interface changes
- Describe specifics on how to test the effects of the patch
- It's better to submit multiple patches with separate bits of functionality than a big patch containing lots of changes
- Only submit a pull request for work you expect to be ready to merge. Work in progress is best discussed in an issue, or on your own repository fork.
- Document your code inline through PHPDoc syntax. See our API documentation for good examples.
- Check and update documentation on docs.silverstripe.org. Check for any references to functionality deprecated or extended through your patch. Documentation changes should be included in the patch.
- When introducing something "noteworthy" (new feature, API change), update the release changelog for the next release this commit will be included in.
- If you get stuck, please post to the forum or for deeper core problems, to the core mailinglist
- When working with the CMS, please read the "CMS Architecture Guide" first
Commit Messages
We try to maintain a consistent record of descriptive commit messages. Most importantly: Keep the first line short, and add more detail below. This ensures commits are easy to browse, and look nice on github.com (more info about proper git commit messages).
As we automatically generate changelogs from them, we need a way to categorize and filter. Please prefix noteworthy commit messages with one of the following tags:
NEWNew feature or major enhancement (both for users and developers)APIAddition of a new API, or modification/removal/deprecation of an existing API. Includes any change developers should be aware of when upgrading.BUGBugfix or minor enhancement on something developers or users are likely to encounter.
All other commits should not be tagged if they are so trivial that most developers can ignore them during upgrades or when reviewing changes to the codebase. For example, adding unit tests or documentation would not be considered "noteworthy". Same goes for version control plumbing like merges, file renames or reverts.
Further guidelines:
- Each commit should form a logical unit - if you fix two unrelated bugs, commit each one separately
- If you are fixing a issue from our bugtracker (cms and framework), please append
(fixes #<ticketnumber>) - When fixing issues across repos (e.g. a commit to
frameworkfixes an issue raised in thecmsbugtracker), use(fixes silverstripe/silverstripe-cms#<issue-number>)(details) - If your change is related to another commit, reference it with its abbreviated commit hash.
- Mention important changed classes and methods in the commit summary.
Example: Bad commit message
finally fixed this dumb rendering bug that Joe talked about ... LOL
also added another form field for password validation
Example: Good commit message
BUG Formatting through prepValueForDB()
Added prepValueForDB() which is called on DBField->writeToManipulation()
to ensure formatting of value before insertion to DB on a per-DBField type basis (fixes #1234).
Added documentation for DBField->writeToManipulation() (related to a4bd42fd).
The steps in more detail
Branch for new issue and develop on issue branch
Before you start working on a new feature or bugfix, create a new branch dedicated to that one change named by issue number and description. If you're working on Issue #100, a DataObject::get_one() bugfix, create a new branch with the issue number and description, like this:
$ git checkout -b 100-dataobject-get-one
Edit and test the files on your development environment. When you've got something the way you want and established that it works, commit the changes to your branch on your local git repo.
$ git add <filename>
$ git commit -m 'Some kind of descriptive message (fixes #100)'
You'll need to use git add for each file that you created or modified. There are ways to add multiple files, but I highly recommend a more deliberate approach unless you know what you're doing.
Then, you can push your new branch to GitHub, like this (replace 100-dataobject-get-one with your branch name):
$ git push origin 100-dataobject-get-one
You should be able to log into your GitHub account, switch to the branch, and see that your changes have been committed. Then click the Pull button to request that your commits get merged into the development master.
Rebase Your Development Branch on the Latest Upstream
To keep your development branch up to date, rebase your changes on top of the current state of the upstream master. See the What is git rebase? section below to learn more about rebasing.
If you've set up an upstream branch as detailed above, and a development branch called 100-dataobject-get-one, you can update upstream and rebase your branch from it like so:
# make sure all your changes are committed as necessary in branch
$ git fetch upstream
$ git rebase upstream/master
Note that the example doesn't keep your own master branch up to date. If you wanted to that, you might take the following approach instead:
# make sure all your changes are committed as necessary in branch
$ git fetch upstream
$ git checkout master
$ git rebase upstream/master
$ git checkout 100-dataobject-get-one
$ git rebase master
You may need to resolve conflicts that occur when a file on the development trunk and one of your files have both been changed. Edit each file to resolve the differences, then commit the fixes to your development server repo and test. Each file will need to be "added" before running a "commit."
Conflicts are clearly marked in the code files. Make sure to take time in determining what version of the conflict you want to keep and what you want to discard.
$ git add <filename>
$ git rebase --continue
Squash All Commits Related to a Single Issue into a Single Commit
Once you have rebased your work on top of the latest state of the upstream master, you may have several commits related to the issue you were working on. Once everything is done, squash them into a single commit with a descriptive message (see "Contributing: Commit Messages").
To squash four commits into one, do the following:
$ git rebase -i upstream/master
In the text editor that comes up, replace the words "pick" with "squash" or just "s" next to the commits you want to squash into the commit before it.
Save and close the editor, and git will combine the "squash"'ed commits with the one before it.
Git will then give you the opportunity to change your commit message to something like, BUG DataObject::get_one() parameter order (fixes #100).
If you want to discard the commit messages from the commits you're squashing and just use the message from your "pick" commit(s) you can use "fixup" or "f" instead of "squash" to bypass the message editing and make the process a bit quicker.
Important: If you've already pushed commits to GitHub, and then squash them locally, you will have to force-push to your GitHub again. Add the -f argument to your git push command:
$ git push -f origin 100-dataobject-get-one
Helpful hint: You can always edit your last commit message by using:
$ git commit --amend
Client-side build tooling
Core JavaScript, CSS, and thirdparty dependencies are managed with the build tooling described below.
Note this only applies to core SilverStripe dependencies, you're free to manage dependencies in your project codebase however you like.
Node.js
The Node.js JavaScript runtime is the foundation of our client-side build tool chain. If you want to do things like upgrade dependencies, make changes to core JavaScript or SCSS files, you'll need Node installed on your dev environment. Our build tooling supports the v4.2.x (LTS) version of Node.
You'll likely want to manage multiple versions of Node, we suggest using Node Version Manager.
npm
npm is the package manager we use for JavaScript dependencies. It comes bundled with Node.js so should already have it installed if you have Node.
The configuration for an npm package goes in package.json. You'll see one in the root
directory of framework. As well as being used for defining dependencies and basic package
information, the package.json file has some other handy features.
npm scripts
The script property of a package.json file can be used to define command line scripts.
A nice thing about running commands from an npm script is binaries located in
node_modules/.bin/ are temporally added to your $PATH. This means we can use dependencies
defined in package.json for things like compiling JavaScript and SCSS, and not require
developers to install these tools globally. This means builds are much more consistent
across development environments.
For more info on npm scripts see https://docs.npmjs.com/misc/scripts
To run an npm script, open up your terminal, change to the directory where package.json
is located, and run $ npm run <SCRIPT_NAME>. Where <SCRIPT_NAME> is the name of the
script you wish to run.
Here are the scripts which are available in framework
Note you'll need to run an npm install to download the dependencies required by these scripts.
build
$ npm run build
Runs a Gulp task which builds the core JavaScript files. You will need to run this script whenever you make changes to a JavaScript file.
Run this script with the --development flag to watch for changes in JavaScript files
and automatically trigger a rebuild.
lint
$ npm run lint
Run eslint over JavaScript files reports errors.
test
$ npm run test
Runs the JavaScript unit tests.
coverage
$ npm run coverage
Generates a coverage report for the JavaScript unit tests. The report is generated
in the coverage directory.
css
$ npm run css
Compile all of the .scss files into minified .css files. Run with the --development flag to
compile non-minified CSS and watch for every time a .scss file is changed.
sprites
$ npm run sprites
Generates sprites from the individual image files in admin/images/sprites/src.
thirdparty
$ npm run thirdparty
Copies legacy JavaScript dependencies from node_modules into the thirdparty directory.
This is only required legacy dependencies which are not written as CommonJS or ES6 modules.
All other modules will be included automatically with the build script.
sanity
$ npm run sanity
Makes sure files in thirdparty match files copied from node_modules. You should never commit
custom changes to a library file. This script will catch them if you do 😄
lock
$ npm run lock
Generates a "shrinkwrap" file containing all npm package versions and writes it to
npm-shrinkwrap.json. Run this command whenever a new package is added to package.json,
or when updating packages. Commit the resulting npm-shrinkwrap.json. This uses a third party
npm-shrinkwrap library
since the built-in npm shrinkwrap (without a dash) has proven unreliable.
Gulp
Gulp is the build system which gets invoked by most npm scripts
in SilverStripe. The gulpfile.js script is where Gulp tasks are defined.
Here are the Gulp tasks which are defined in gulpfile.js
build
This is where JavaScript files are compiled and bundled. There are two parts to this which are important to understand when working core JavaScript files.
Babel
Babel is a JavaScript compiler. It takes JavaScript files as input, performs some transformations, and outputs other JavaScript files. In SilverStripe we use Babel to transform our JavaScript in two ways.
Transforming ES6
ECMAScript 6 (ES6) is the newest version of the ECMAScript standard. It has some great new features, but the browser support is still patchy, so we use Babel to transform ES6 source files back to ES5 files for distribution.
To see some of the new features check out https://github.com/lukehoban/es6features
Transforming to UMD
Universal Module Definition (UMD) is a pattern for writing
JavaScript modules. The advantage of UMD is modules can be 'required' by module loaders
(AMD and ES6 / CommonJS) and can also be loaded via <script> tags. Here's a simple example.
(function (global, factory) {
if (typeof define === 'function' && define.amd) {
// AMD
define(['jQuery'], factory);
} else if (typeof exports === 'object') {
// CommonJS
module.exports = factory(require('jQuery'));
} else {
// Default browser with no bundling (global is window)
global.MyModule = factory(global.jQuery);
}
}(this, function (jQuery) {
// Module code here
}));
The UMD wrapper is generated by Babel so you'll never have to write it manually, it's handled for you by the build task.
Browserify
One of the great new features in ES6 is support for native modules. In order to support modules, SilverStripe uses Browserify to bundle modules for distribution.
Browserify takes an entry file, creates an abstract syntax tree (AST) by recursively
looking up all the require statements it finds, and outputs a bundled JavaScript file which
can be executed in a browser.
In addition to being a concatenated JavaScript file, Browserify bundles contain a lightweight
require() implementation, and an API wrapper which allows modules to require each other at
runtime. In most cases modules will bundled together in one JavaScript file, but it's also
possible to require modules bundled in another file, these are called external dependencies.
In this example the BetterField module requires jQuery from another bundle.
gulpfile.js
gulp.task('bundle-a', function () {
return browserify()
.transform(babelify.configure({
presets: ['es2015'] // Transform ES6 to ES5.
}))
.require('jQuery', { expose: 'jQuery' }) // Make jQuery available to other bundles at runtime.
.bundle()
.pipe(source('bundle-a.js'))
.pipe(gulp.dest('./dist'));
});
This generates a bundle bundle-a.js which includes jQuery and exposed it to other bundles.
better-field.js
import $ from 'jQuery';
$('.better-field').fadeIn();
gulpfile.js
...
gulp.task('bundle-better-field', function () {
return browserify('./src/better-field.js')
.transform(babelify.configure({
presets: ['es2015'] // Transform ES6 to ES5.
}))
.external('jQuery') // Get jQuery from another bundle at runtime.
.bundle()
.pipe(source('bundle-b.js'))
.pipe(gulp.dest('./dist'));
});
When Browserify bundles ./src/better-field.js (the entry file) it will ignore all
require statements that refer to jQuery and assume jQuery will be available via another
bundle at runtime.
The advantage of using externals is a reduced file size. The browser only needs to download
jQuery once (inside bundle-a.js) rather than it being included in multiple bundles.
Core dependencies are are bundled and exposed in the bundle-lib.js file. Most of the libraries
a CMS developer requires are available a externals in that bundle.
Some gotchas
Be careful not to commit any of your configuration files, logs, or throwaway test files to your GitHub repo. These files can contain information you wouldn't want publicly viewable and they will make it impossible to merge your contributions into the main development trunk.
Most of these special files are listed in the .gitignore file and won't be included in any commit, but you should carefully review the files you have modified and added before staging them and committing them to your repo. The git status command will display detailed information about any new files, modifications and staged.
$ git status
One thing you do not want to do is to issue a git commit with the -a option. This automatically stages and commits every modified file that's not expressly defined in .gitignore, including your crawler logs.
$ git commit -a
Sometimes, you might correct an issue which was reported in a different repo. In these cases, don't simply refer to the issue number as GitHub will infer that as correcting an issue in the current repo. In these cases, use the full GitHub path to reference the issue.
$ git commit -m 'Issue silverstripe/silverstripe-cms#100: Some kind of descriptive message'
Sometimes, you might correct an issue which was reported in a different repo. In these cases, don't simply refer to the issue number as GitHub will infer that as correcting an issue in the current repo. See Commit Messages above for the correct way to reference these issues.
What is git rebase?
Using git rebase helps create clean commit trees and makes keeping your code up-to-date with the current state of the upstream master easy. Here's how it works.
Let's say you're working on Issue #212 a new plugin in your own branch and you start with something like this:
1---2---3 #212-my-new-plugin
/
A---B #master
You keep coding for a few days and then pull the latest upstream stuff and you end up like this:
1---2---3 #212-my-new-plugin
/
A---B--C--D--E--F #master
So all these new things (C,D,..F) have happened since you started. Normally you would just keep going (let's say you're not finished with the plugin yet) and then deal with a merge later on, which becomes a commit, which get moved upstream and ends up grafted on the tree forever.
A cleaner way to do this is to use rebase to essentially rewrite your commits as if you had started at point F instead of point B. So just do:
git rebase master 212-my-new-plugin
git will rewrite your commits like this:
1---2---3 #212-my-new-plugin
/
A---B--C--D--E--F #master
It's as if you had just started your branch. One immediate advantage you get is that you can test your branch now to see if C, D, E, or F had any impact on your code (you don't need to wait until you're finished with your plugin and merge to find this out). And, since you can keep doing this over and over again as you develop your plugin, at the end your merge will just be a fast-forward (in other words no merge at all).
So when you're ready to send the new plugin upstream, you do one last rebase, test, and then merge (which is really no merge at all) and send out your pull request. Then in most cases, we have a simple fast-forward on our end (or at worst a very small rebase or merge) and over time that adds up to a simpler tree.
More info on the "Rebasing" chapter on git-scm.com and the git rebase man page.
License
Portions of this guide have been adapted from the "Thinkup" developer guide, with friendly permission from Gina Trapani/thinkupapp.com.