16 KiB
第一章:输入输出模型
1.1 回顾冯·诺依曼体系结构
冯·诺依曼体系结构的理论要点如下:- ① 存储程序:
程序指令和数据都存储在计算机的内存中,这使得程序可以在运行时修改。 - ② 二进制逻辑:所有
数据和指令都以二进制形式表示。 - ③ 顺序执行:指令按照它们在内存中的顺序执行,但可以有条件地改变执行顺序。
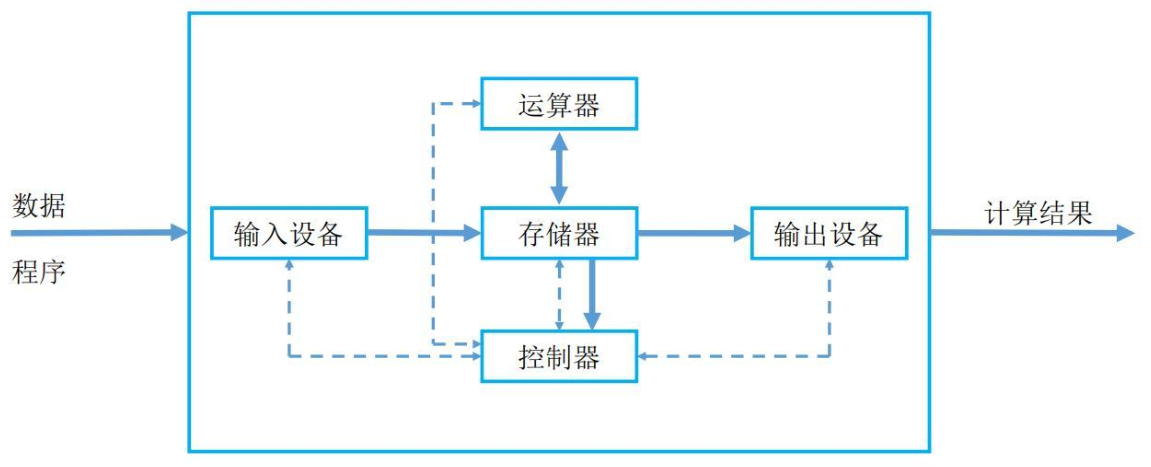
- ④ 五大部件:计算机由
运算器、控制器、存储器、输入设备和输出设备组成。 - ⑤ 指令结构:指令由操作码和地址码组成,操作码指示要执行的操作,地址码指示操作数的位置。
- ⑥ 中心化控制:计算机的控制单元(CPU)负责解释和执行指令,控制数据流。
- ① 存储程序:
Note
上述的组件协同工作,构成了一个完整的计算机系统:
运算器和控制器通常被集成在一起,组成中央处理器(CPU),负责数据处理和指令执行。存储器(内存)保存数据和程序,是计算机运作的基础。输入设备和输出设备负责与外界的交互,确保用户能够输入信息并接收计算机的处理结果。直到今天,虽然硬件的发展日新月异,但是现代计算机的硬件理论基础还是《冯·诺依曼体系结构》。
1.2 冯·诺依曼体系结构的瓶颈
- 计算机是有性能瓶颈的:如果 CPU 有每秒处理 1000 个服务请求的能力,各种总线的负载能力能达到 500 个, 但网卡只能接受 200个请求,而硬盘只能负担 150 个的话,那这台服务器得处理能力只能是 150 个请求/秒,有 85% 的处理器计算能力浪费了,在计算机系统当中,
硬盘的读写速率已经成为影响系统性能进一步提高的瓶颈。

- 计算机的各个设备部件的延迟从高到低的排列,依次是机械硬盘(HDD)、固态硬盘(SSD)、内存、CPU 。

- 从上图中,我们可以知道,CPU 是最快的,一个时钟周期是 0.3 ns ,内存访问需要 120 ns ,固态硬盘访问需要 50-150 us,传统的硬盘访问需要 1-10 ms,而网络访问是最慢,需要 40 ms 以上。
Note
时间的单位换算如下:
- ① 1 秒 = 1000 毫秒,即 1 s = 1000 ms。
- ② 1 毫秒 = 1000 微妙,即 1 ms = 1000 us 。
- ③ 1 微妙 = 1000 纳秒,即 1 us = 1000 ns。
- 如果按照上图,将计算机世界的时间和人类世界的时间进行对比,即:
如果 CPU 的时钟周期按照 1 秒计算,
那么,内存访问就需要 6 分钟;
那么,固态硬盘就需要 2-6 天;
那么,传统硬盘就需要 1-12 个月;
那么,网络访问就需要 4 年以上。
Note
- ① 这就中国古典修仙小说中的“天上一天,地上一年”是多么的相似!!!
- ② 对于 CPU 来说,这个世界真的是太慢了!!!
- 其实,中国古代中的文人,通常以
蜉蝣来表示时间的短暂(和其他生物的寿命比),也是类似的道理,即:
鹤寿千岁,以极其游,蜉蝣朝生而暮死,尽其乐,盖其旦暮为期,远不过三日尔。
--- 出自 西汉淮南王刘安《淮南子》
寄蜉蝣于天地,渺沧海之一粟。 哀吾生之须臾,羡长江之无穷。
挟飞仙以遨游,抱明月而长终。 知不可乎骤得,托遗响于悲风。
--- 出自 苏轼《赤壁赋》
Note
- ① 从
蜉蝣的角度来说,从早到晚就是一生;但是,从人类角度来说,从早到晚却仅仅只是一天。- ② 这和“天上一天,地上一年”是多么的相似,即:如果
蜉蝣是人类的话,那我们就是仙人了。
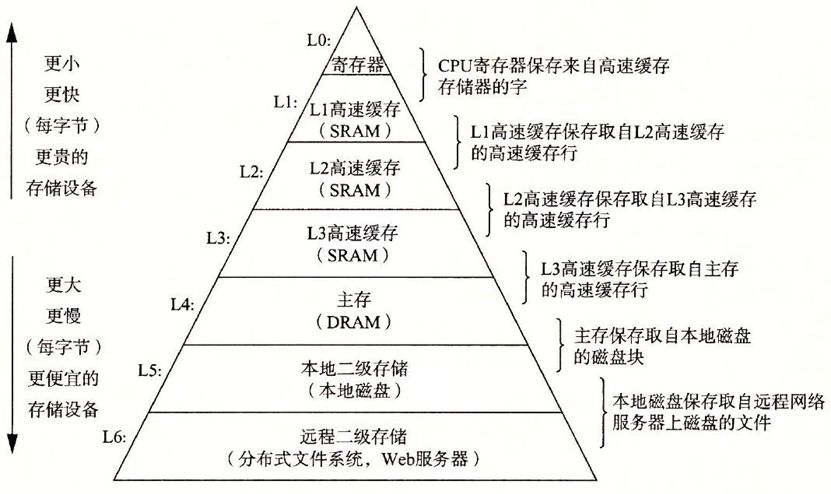
- 存储器的层次结构(CPU 中也有存储器,即:寄存器、高速缓存 L1、L2 和 L3),如下所示:
Note
上图以层次化的方式,展示了价格信息,揭示了一个真理,即:鱼和熊掌不可兼得。
- ① 存储器越往上速度越快,但是价格越来越贵, 越往下速度越慢,但是价格越来越便宜。
- ② 正是由于计算机各个部件的速度不同,容量不同,价格不同,导致了计算机系统/编程中的各种问题以及相应的解决方案。
- 正是由于 CPU、内存以及 I/O 设备之间的速度差异,从而导致了计算机的性能瓶颈,即所谓的
“冯·诺依曼体系结构的瓶颈”。

- 因为 CPU 的处理速度远远快于内存和 I/O 设备,导致在等待数据处理和传输的时候,CPU 大部分处于空闲状态。就是这种显著的速度差异就导致了计算机的性能瓶颈,限制了整个计算机系统的效率。
Note
- 对于硬件的这种显著的速度差异,我们程序员是无法解决的。
- 但是,为了平衡三者之间的速度鸿沟,我们可以通过引入
缓冲区技术,来降低系统的 I/O 次数,降低系统的开销。
- 其实,在硬件上也是有
缓冲区的,即:CPU 内部集成了缓存,将经常使用到的数据从内存中加载到缓存中。
Note
对于缓存和内存中数据的同步解决方案,会有各种各样的算法,如:LRU 等。

1.3 缓冲区
1.3.1 如果存在缓冲区,键盘输入的数据是怎么到达程序的?
-
当我们在键盘上输入数据并传递给程序时,通常会经历如下的几个步骤:
- ①
键盘生成输入信号:当我们在键盘上按下某个键的时候,键盘会将这个动作转换为对应的电信号,传递给键盘控制器。 - ②
键盘控制器发送中断信号:计算机的键盘控制器会检测到按键动作,向 CPU 发送中断请求。 - ③
CPU 执行中断处理程序:CPU 暂停当前任务,进入中断处理状态,操作系统的中断处理程序接收并处理键盘输入。 - ④
操作系统将输入存入缓冲区:键盘输入的数据被存入内存缓冲区,操作系统会将这些数据暂时存放在缓冲区中,等待程序从缓冲区中读取数据。 - ⑤
程序读取数据:程序通过读取函数从缓冲区读取数据进行处理。
- ①
-
其对应的图示,如下所示:

Important
其实,C 语言中的
printf函数和scanf函数,其内部就使用了缓冲区。
- ① 当我们使用
printf函数输出数据的时候,数据并不会立即就写出到输出设备(如:屏幕等)。而是先将其放置到stdout 缓冲区中,然后在满足条件的时候,再从缓冲区中刷新到输出设备。- ② 当我们使用
scanf函数输入数据的时候,数据并不会立即就从输入设备中读取(如:键盘等)。而是先将其放置到stdin 缓冲区中,然后在满足条件的时候,再从缓冲区中加载数据。
1.3.2 如果没有缓冲区,键盘输入的数据是怎么到达程序的?
-
当我们在键盘上输入数据并传递给程序时,通常会经历如下的几个步骤:
- ①
键盘生成输入信号:当我们在键盘上按下某个键的时候,键盘会将这个动作转换为对应的电信号,传递给键盘控制器。 - ②
键盘控制器发送中断信号:键盘控制器检测到按键动作,向 CPU 发送中断请求,通知操作系统有输入数据。 - ③
操作系统处理输入:操作系统接收到中断信号后,立即获取键盘数据并处理。由于没有缓冲区,操作系统必须将数据立即传递给程序。 - ④
程序直接读取数据:程序必须在键盘每次输入后立即读取数据,并且处理这个输入,不会有任何数据被暂存或积累。
- ①
-
其对应的图示,如下所示:

Note
如果没有缓冲区,键盘输入的数据将无法有效地被程序管理和处理,系统的工作效率会显著下降,具体影响体现在以下几个方面:
- ①
程序与设备的频繁交互:在没有缓冲区的情况下,程序需要直接与键盘设备进行交互。这意味着每次按键输入,操作系统都必须立即将数据传递给程序处理。这样会带来以下问题:
- 频繁的 I/O 操作:每一次键盘输入都会触发一个 I/O 操作,将数据直接传输给程序。程序必须每次都立即响应输入设备,执行读操作,导致程序处理器频繁被中断。
- 实时响应要求:程序需要时刻等待并响应输入,哪怕是输入非常小的数据(比如一个字符),程序都必须立即读取并处理。这对程序的设计提出了很高的实时性要求,可能会降低程序的运行效率。
- ②
处理效率低下:由于没有缓冲区,程序无法积累多个输入数据再进行批量处理。每一次输入必须立即处理,程序执行的效率会受到影响:
- I/O 阻塞:程序可能会因为等待输入设备的响应而阻塞。没有缓冲区的情况下,程序不能继续执行其他任务,必须等待每一次输入完成后才能继续执行其他操作。
- 浪费系统资源:程序频繁地切换到处理 I/O 操作,导致处理器资源被大量占用。在处理较大数据量时,这种方式的效率极低,容易造成资源浪费。
- ③
用户体验差:从用户角度来看,程序对键盘输入的响应会显得非常僵硬,无法处理多个输入操作的积累:
- 输入延迟:程序必须实时处理每个键盘输入,用户输入数据的速度一旦超过程序的处理能力,可能导致输入延迟或丢失输入。
- 无法处理复杂输入:如果用户需要输入多个字符或进行复杂的输入操作(比如连续输入多个命令),程序可能难以一次性正确处理,因为它只能逐一处理每一个输入,而无法一次性获取多个输入进行批量处理。
1.3.3 缓冲区的好处
- 使用缓冲区的好处:
减少了 I/O 操作的频率,降低了系统资源的消耗,提高了系统的性能,提升了用户的使用体验。
1.3.4 缓冲区是如何提高 I/O 操作的频率?
- 对于 C 语言中的
printf函数和 scanf 函数,其功能如下:printf函数:将程序中的数据输出到外部设备(如:显示器)中。scanf函数:从外部设备(如:键盘)中读取数据到程序中。
- 这些都是非常典型的 I/O 操作,并且 I/O 过程的效率也是很低的。除了硬件性能本身的差异外,I/O 操作的复杂性也是非常重要的因素,每次 I/O 操作都会带来一些固定的开销,如:
- ① 每次 I/O 操作都需要设备初始化和响应等待。
- ② 操作系统管理 I/O 请求,涉及中断处理和上下文切换,这些都消耗了大量时间。
- ③ 应用从用户态切换到内核态的系统调用也会带来额外的时间开销。(I/O 操作普遍涉及系统调用)
- ④ ...
- 如果每输入一个字符或每输出一个字符都需要进行一次完整的 I/O 操作,那么这些固定的开销会迅速积累,进而导致系统的性格显著下降。
- 硬件层面的效率低下,我们没有办法通过软件层面的优化去解决。但对于这些大量的固定开销,我们可以通过
缓冲区来进行效率优化。
Important
- ① 缓冲区的主要目的是暂时存储数据,然后在适当的时机一次性进行大量的 I/O 操作。
- ② 这样,多个小的 I/O 请求可以被组合成一个大 I/O 的请求,有效地分摊了固定开销,并显著提高了总体性能。
- 对于
scanf函数而言,当用户通过键盘输入字符的时候,这些输入的字符首先被保存在stdin的缓冲区中,,当满足某个触发条件后,才传递给程序处理。这样就减少了总的 I/O 次数,提高了效率。 - 对于
printf函数而言,输出的内容首先会保存到stdout的缓冲区中,当满足某个触发条件后,这些内容会一次性写入并显示到屏幕,降低了与显示设备的交互频率。
Note
- ① 如果你还不能理解,就可以将 I/O 操作,看做是搬家。对于搬家而言,需要搬运东西的总量是固定的,搬一趟的时间也是差不多的。我们当然希望:一次性搬的东西尽量多,搬运的次数尽量少,这样总耗时就少。
- ② 不使用缓冲区,就类似每次搬家只能手提一个东西,需要频繁的往返。而使用缓冲区,就好比我们使用一个小推车,可以一次性的搬运多个东西,极大的提高了效率。
1.3.5 缓冲区的分类
-
从上述的内容中,我们可以明确到看到缓冲区有一个显著的特点:
当满足某个触发条件后,程序会开始对缓冲区的数据执行输入或输出操作。而这种满足某个条件,就触发数据传输的行为,就称为缓冲区的自动刷新机制。 -
基于这种自动刷新的触发条件的不同,我们可以将缓冲区划分为以下三种类型:
- ①
全缓冲(满缓冲):仅当缓冲区达到容量上限时,缓冲区才会自动刷新,并开始处理数据。否则,数据会持续积累在缓冲区中直到缓冲区满触发自动刷新。文件操作的输出缓冲区便是这种类型的经典例子。 - ②
行缓冲:缓冲区一旦遇到换行符,缓冲区就会自动刷新,所有数据都会被传输。stdout缓冲区就是典型的行缓冲区。 - ③
无缓冲(不缓冲):在此模式下,数据不经过中间的缓冲步骤,每次的输入或输出操作都会直接执行。这种方法适用于需要快速、实时响应的场合。stderr(标准错误输出)就是这种方式,它经常被用来即时上报错误信息。
- ①
-
之前,我们经常会在代码中,会加入以下的代码,其实就是为了让行缓冲变为无缓冲,如下所示:
#include <stdI/O.h>
int main() {
// 禁用 stdout 缓冲区
setbuf(stdout, nullptr);
int num = 0;
printf("请输入一个整数:");
scanf("%d", &num);
printf("你输入的整数是:%d\n", num);
return 0;
}
- 如果不加入上述的代码,将会这样显示:

- 但是,一旦我们加入了上述的代码,将会这样显示:

Note
- ① setbuf 是 C 语言标准库中的一个函数,用于设置文件流的缓冲区。它允许程序员控制 I/O 操作的缓冲行为,从而影响文件流(如
stdin、stdout或文件指针FILE *类型)的效率和顺序。- ② 其定义,如下所示:
/** * @param stream 缓冲区的文件流 * @param buf 用户提供的缓冲区,如果为 NULL,就是禁用缓冲 */ void setbuf(FILE *stream, char *buf);
- ③ 不同的编译器和开发环境可能会对输出缓冲进行特殊设置,尤其是在调试模式下,以便提供更好的调试体验,例如:微软的 MSVC 在 debug 模式下,即使没有换行符,printf 函数的输出通常也会立即显示在控制台上。这种行为是为了帮助程序员更有效地调试程序,即时看到他们的输出,而不需要等待缓冲区刷新条件。但是,遗憾的是,GCC 在 debug 模式中,并没有这么做!!!
Important
① 无论是哪种类型的缓冲区,当缓冲区满了时,都会触发自动刷新。
全缓冲区:唯一的自动刷新条件是缓冲区满。
行缓冲区:除了缓冲区满导致的自动刷新,还有遇到换行符的自动刷新机制。
② 手动刷新:大多数缓冲区提供了手动刷新的机制,如:使用
fflush函数来刷新 stdout 缓冲区,也可以使用setbuf函数来禁用缓冲区。③
输出缓冲区中的数据需要刷新才能输出到目的地,但输入缓冲区通常不需要刷新,强制刷新输入缓冲区往往会引发未定义行为。④ 当程序执行完毕(如:main函数返回)时,缓冲区通常会自动刷新,除此之外,还有一些独特的机制也可以刷新缓冲区。但这些机制可能因不同的编译器或平台而异,不能作为常规手段。
强烈建议依赖手动或者常规自动刷新的机制来完成缓冲区的刷新。